Nhóm MBA Bách Khoa giới thiệu đến bạn quy trình 13 bước chạy luận văn dữ liệu bảng panel bằng Stata. Luận văn thạc sĩ định lượng Stata trong bài này thuộc dạng định lượng, dữ liệu có được thông qua số liệu thứ cấp như là các chỉ số kinh tế vĩ mô, GDP, ROA, ROE… Phân tích dữ liệu bảng panel là một kỹ thuật phổ biến trong các nghiên cứu kinh tế, đặc biệt là việc làm các đề tài luận văn định lượng về tài chính, chứng khoán, ngân hàng… giúp kiểm tra mối quan hệ giữa các biến qua thời gian.
Dưới đây là quy trình chi tiết 13 bước để chạy luận văn dữ liệu bảng panel bằng phần mềm Stata.
1. Lập mô hình nghiên cứu
Để bắt đầu, cần xác định rõ ràng câu hỏi nghiên cứu của đề tài và các giả thuyết cần kiểm tra.
Ví dụ tên đề tài là: Các yếu tố tác động đến tỷ suất sinh lợi của các ngân hàng TMCP tại Việt Nam
Mô hình nghiên cứu bao gồm xác định 1 biến phụ thuộc và các biến độc lập. Ví dụ, nếu bạn đang nghiên cứu Các yếu tố tác động đến tỷ suất sinh lợi của các ngân hàng TMCP tại Việt Nam, biến phụ thuộc là Tỷ suất sinh lợi của các ngân hàng TMCP tại Việt Nam, trong khi các biến độc lập là: quy mô của ngân hàng, dư nợ cho vay khách hàng của ngân hàng,quy mô vốn chủ sở hữu của ngân hàng….
Một khi mô hình đã được xác định, cần viết ra dưới dạng một phương trình toán học, và các biến độc lập và phụ thuộc được định nghĩa như sau:

2. Thu thập số liệu thứ cấp
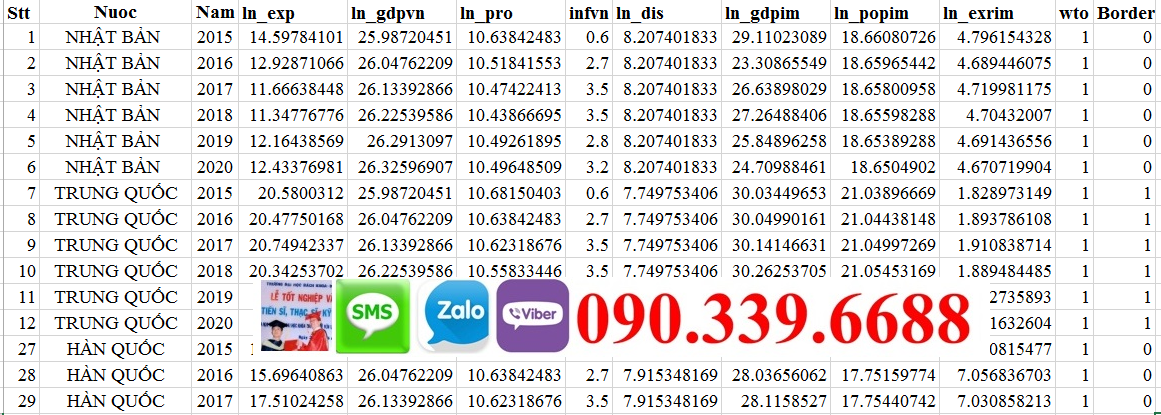
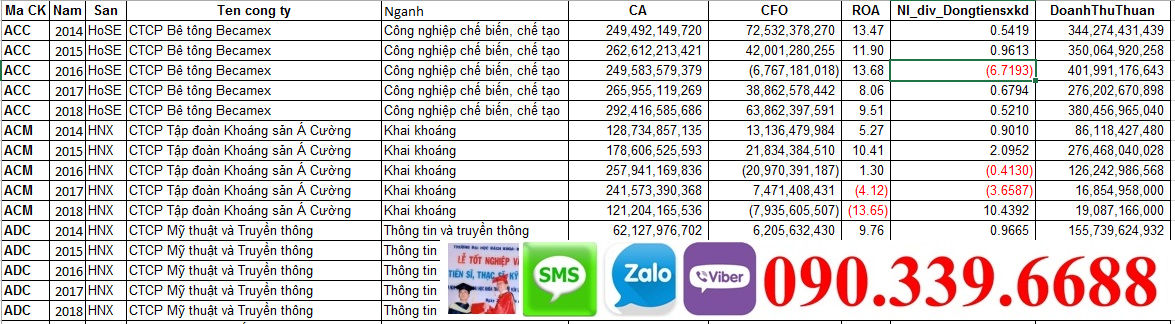
Thu thập dữ liệu là bước quan trọng tiếp theo. Dữ liệu bảng panel bao gồm dữ liệu theo dõi các đối tượng nghiên cứu qua nhiều thời gian. Ví dụ, dữ liệu có thể đến từ các cuộc điều tra hàng năm của các tổ chức chính phủ hoặc công ty chứng khoán, dữ liệu từ các cơ sở dữ liệu công cộng như World Bank, IMF, hoặc các báo cáo tài chính của công ty( thường thấy mọi người lấy ở vietstock )
Quan trọng là dữ liệu phải đầy đủ, chính xác và có độ tin cậy cao. Bạn cần kiểm tra tính nhất quán về đơn vị đo lường và sự thiếu sót trong dữ liệu trước khi sử dụng cho phân tích.
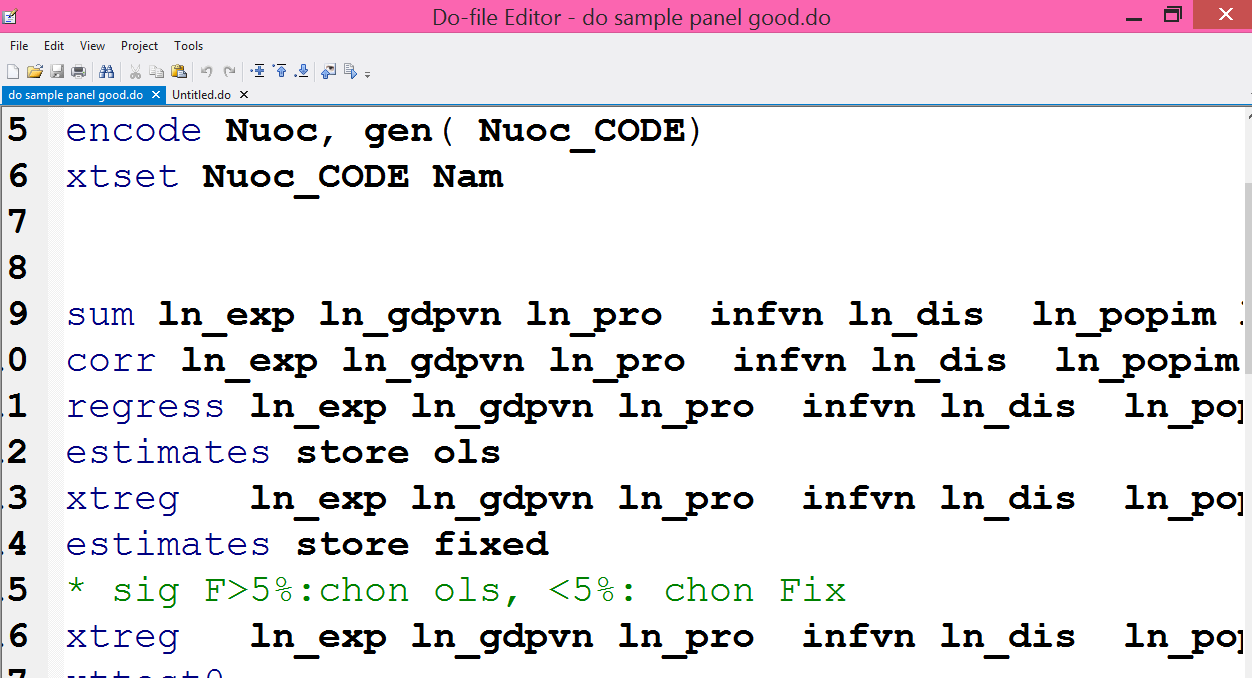
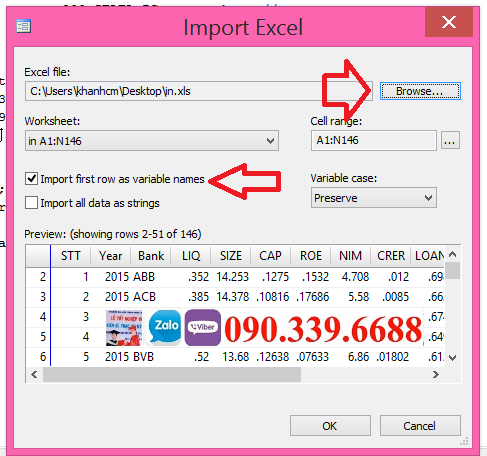
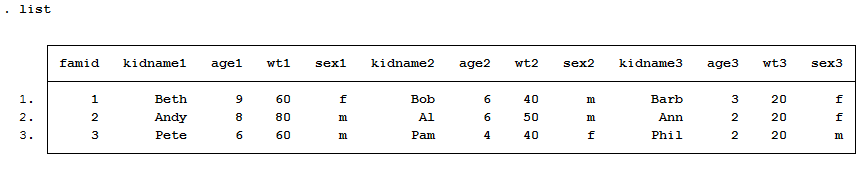
3. Đưa số liệu từ Excel vào Stata
Sau khi thu thập và làm sạch dữ liệu, bạn cần nhập chúng vào Stata. Để làm điều này, trước hết, lưu dữ liệu trong Excel dưới định dạng .xlsx. Sử dụng lệnh "import excel" để nhập dữ liệu vào Stata:
import excel " ", sheet("") firstrow
Lệnh trên sẽ nhập dữ liệu từ excel và hàng đầu tiên là tên các biến.
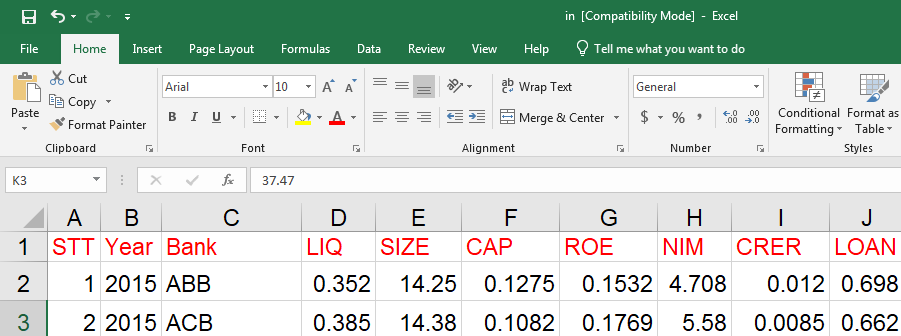
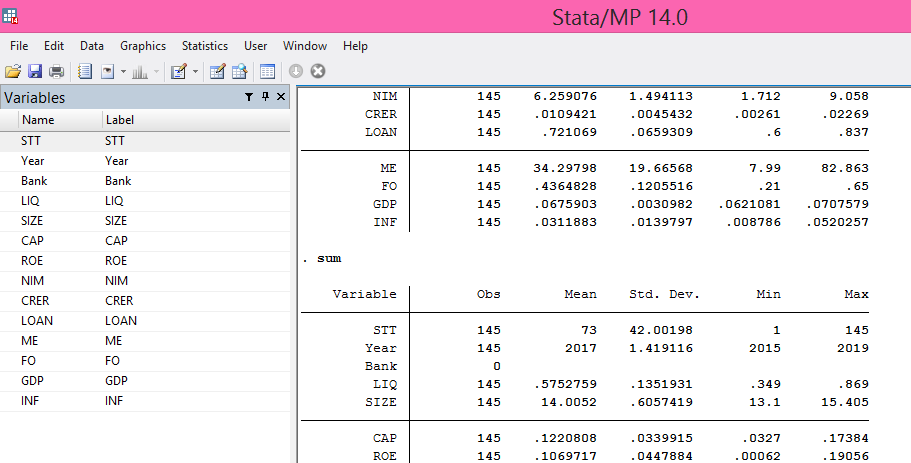
4. Chạy thống kê mô tả
Trước khi tiến hành phân tích sâu, chạy thống kê mô tả giúp ta hiểu rõ hơn về đặc điểm cơ bản của dữ liệu. Thống kê mô tả bao gồm các giá trị trung bình, độ lệch chuẩn, giá trị lớn nhất và nhỏ nhất, cũng như số lượng quan sát của mỗi biến.
Lệnh "summarize" trong Stata sẽ cung cấp một bản tóm tắt các đặc điểm chính của dữ liệu.
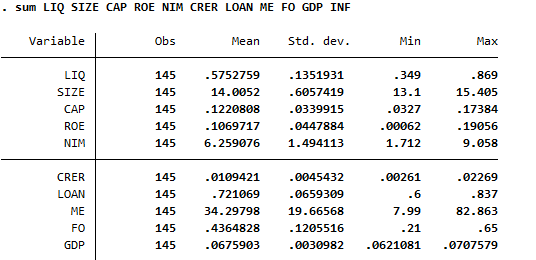
5. Chạy tương quan
Phân tích tương quan giúp xác định mối quan hệ tuyến tính giữa các biến. Ma trận tương quan sẽ cho thấy mức độ và chiều hướng của mối quan hệ giữa các biến. Tương quan có thể dao động từ -1 đến 1, giá trị càng gần 1 hoặc -1 chỉ ra mối quan hệ mạnh giữa cặp biến đó
correlate bien1 bien2 bien3
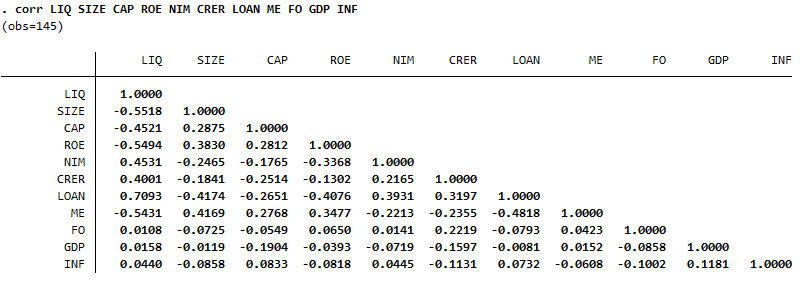
Việc này giúp ta phát hiện các mối quan hệ bất thường hoặc mạnh mẽ giữa các biến, từ đó có thể điều chỉnh mô hình cho phù hợp hơn, vì nếu các biến độc lập quan hệ với nhau quá mạnh có thể sinh ra đa cộng tuyến.
6. Chạy hồi quy OLS
Hồi quy OLS (Ordinary Least Squares) là phương pháp cơ bản để ước lượng mối quan hệ giữa biến phụ thuộc và các biến độc lập.
regress bien_phu_thuoc bien_doc_lap1 bien_doc_lap2
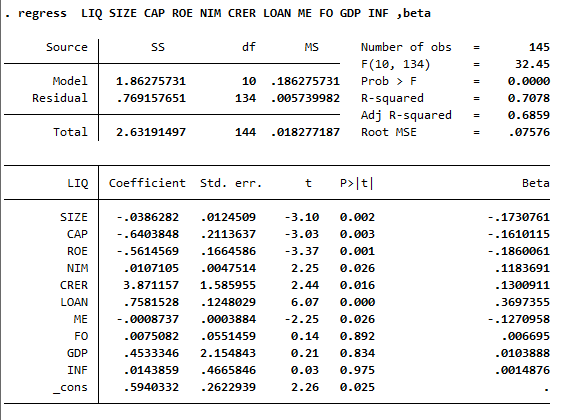
Lệnh "regress" trong Stata sẽ cho ta biết các hệ số hồi quy, giá trị p, và các chỉ số thống kê khác. Tuy nhiên, OLS không thể kiểm soát hiệu ứng theo không gian hoặc thời gian, do đó kết quả có thể bị thiên lệch nếu có sự khác biệt không quan sát được giữa các đối tượng theo không gian hoặc thời gian.
7. Chạy hồi quy hiệu ứng cố định
Hồi quy hiệu ứng cố định (Fixed Effects) giúp kiểm soát các yếu tố không quan sát được mà có thể khác nhau giữa các đối tượng nhưng không thay đổi theo thời gian.
xtreg bien_phu_thuoc bien_doc_lap1 bien_doc_lap2, fe
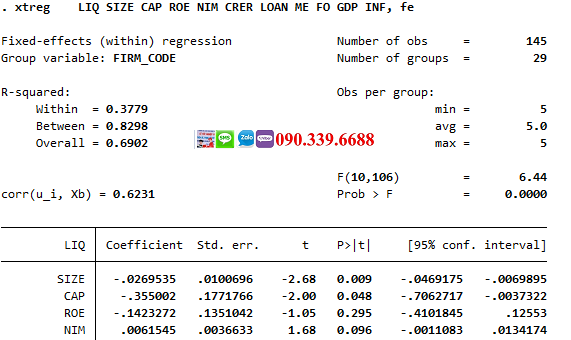
Lệnh "xtreg" với tùy chọn "fe" trong Stata sẽ loại bỏ các biến không thay đổi theo thời gian bằng cách chuyển đổi dữ liệu. Mô hình này giả định rằng các đặc điểm không quan sát được của các đơn vị nghiên cứu là khác nhau nhưng cố định trong suốt khoảng thời gian nghiên cứu.
8. Chạy hồi quy hiệu ứng ngẫu nhiên
Hồi quy hiệu ứng ngẫu nhiên (Random Effects) giả định rằng các yếu tố không quan sát được là ngẫu nhiên và không có tương quan với các biến độc lập. Điều này cho phép các biến không thay đổi theo thời gian vẫn có thể tham gia vào mô hình.
xtreg bien_phu_thuoc bien_doc_lap1 bien_doc_lap2, re
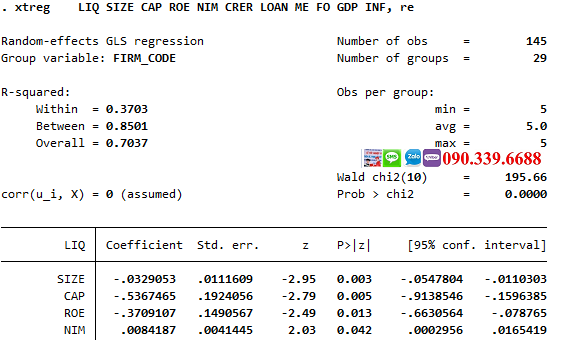
Lệnh "xtreg" với tùy chọn "re" trong Stata sẽ thực hiện hồi quy hiệu ứng ngẫu nhiên, giúp ước lượng các hệ số hồi quy với giả định rằng các sai số ngẫu nhiên là không tương quan với các biến độc lập.
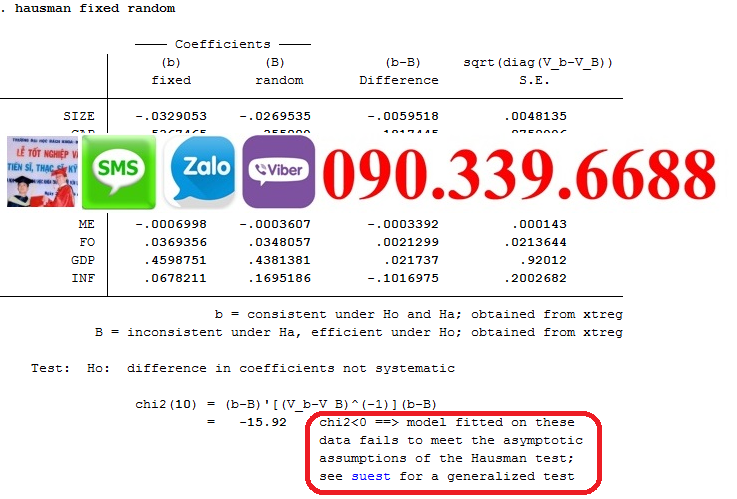
9. Kiểm định Hausman để chọn mô hình
Để xác định xem mô hình hiệu ứng cố định hay ngẫu nhiên là phù hợp hơn, bạn cần thực hiện kiểm định Hausman. Kiểm định này so sánh các ước lượng của hai mô hình và kiểm tra xem sự khác biệt có ý nghĩa thống kê hay không.
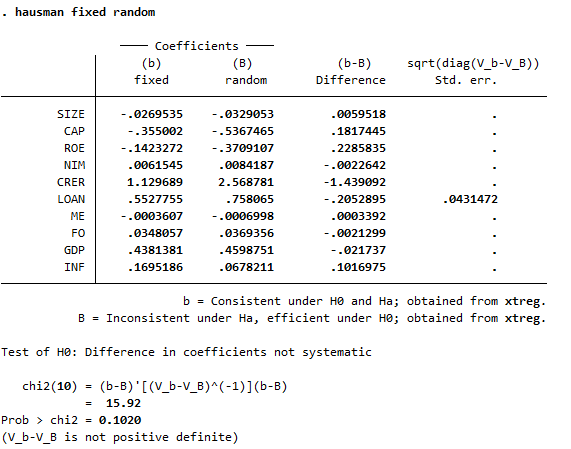
hausman fixed random
Nếu giá trị p của kiểm định Hausman nhỏ hơn 0.05, bạn sẽ chọn mô hình hiệu ứng cố định, vì nó cho thấy rằng các ước lượng của hiệu ứng cố định và ngẫu nhiên khác nhau có ý nghĩa, nghĩa là giả định của mô hình hiệu ứng ngẫu nhiên không đúng.
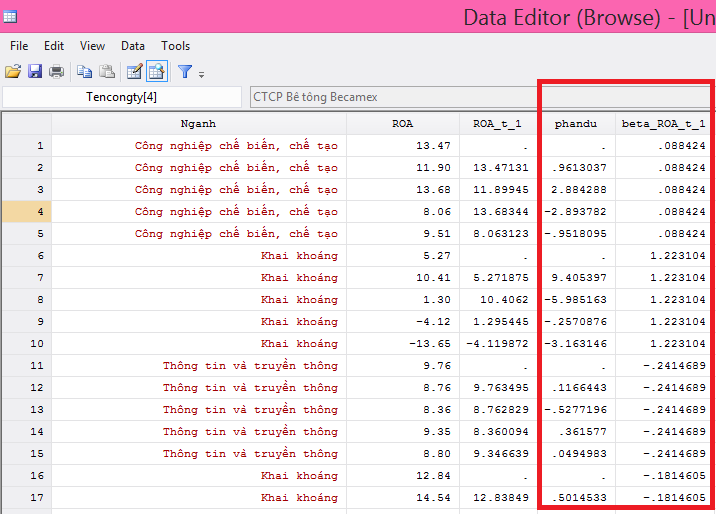
10. Đánh giá đa cộng tuyến
Đa cộng tuyến xảy ra khi các biến độc lập có mối quan hệ tuyến tính mạnh mẽ với nhau, gây khó khăn cho việc ước lượng chính xác các hệ số hồi quy. Ta có thể kiểm tra đa cộng tuyến bằng cách tính hệ số phóng đại phương sai (VIF – Variance Inflation Factor).
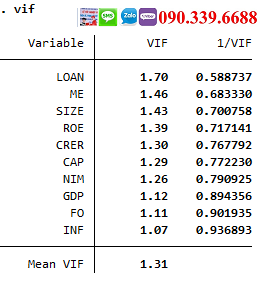
Nếu VIF của một biến lớn hơn 10, điều này có thể chỉ ra rằng biến đó có vấn đề về đa cộng tuyến và cần được xử lý, chẳng hạn như bằng cách loại bỏ biến hoặc kết hợp các biến lại với nhau.
11. Đánh giá phương sai thay đổi
Phương sai thay đổi (Heteroskedasticity) là hiện tượng mà phương sai của sai số thay đổi theo giá trị của các biến độc lập. Điều này có thể làm sai lệch các ước lượng hồi quy. Để kiểm tra hiện tượng này trong dữ liệu bảng panel, ta có thể sử dụng lệnh "xttest0" hoặc "xttest3" trong Stata.
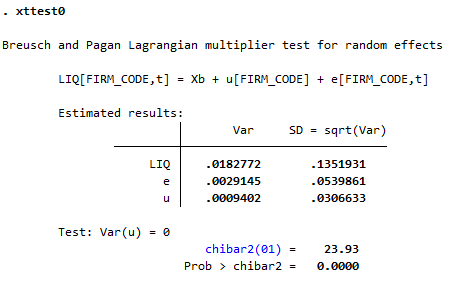
Lệnh "xttest0" hoặc "xttest3" trong Stata được sử dụng để kiểm định phương sai thay đổi trong mô hình hồi quy hiệu ứng cố định hoặc ngẫu nhiên. Lệnh này sẽ giúp bạn phát hiện xem có tồn tại phương sai thay đổi trong dữ liệu của mình hay không.
Kết quả của kiểm định sẽ cho biết liệu có tồn tại phương sai thay đổi trong mô hình hay không. Nếu giá trị p của kiểm định nhỏ hơn mức ý nghĩa 0.05, thì bạn có thể kết luận rằng có hiện tượng phương sai thay đổi. Và bạn cần phải khắc phục vấn đề này.
Nếu bạn phát hiện ra rằng có phương sai thay đổi, bạn có thể sử dụng các phương pháp như ước lượng sai số chuẩn mạnh (robust standard errors) hoặc hồi quy bình phương tổng quát (GLS) để khắc phục
12. Đánh giá tự tương quan
Tự tương quan (Autocorrelation) xảy ra khi các sai số hồi quy có tương quan với nhau qua thời gian, điều này thường gặp trong dữ liệu bảng panel. Kiểm định Wooldridge giúp phát hiện tự tương quan trong dữ liệu bảng panel.

Nếu xtserial cho ra kiểm định Wooldridge cho thấy có tự tương quan, bạn cần thực hiện các biện pháp để khắc phục như bên dưới.
13. Khắc phục phương sai thay đổi, tự tương quan nếu có bằng GLS
Nếu phát hiện có phương sai thay đổi hoặc tự tương quan, bạn có thể sử dụng hồi quy bình phương tổng quát (GLS – Generalized Least Squares) để khắc phục. GLS cho phép xử lý dữ liệu có cấu trúc sai số phức tạp, đảm bảo các ước lượng hồi quy là chính xác hơn.
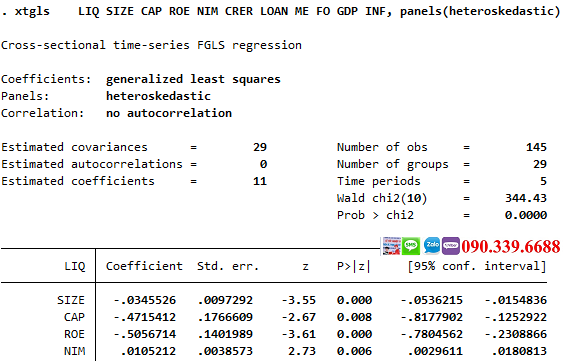
xtgls bien_phu_thuoc bien_doc_lap1 bien_doc_lap2, panels(correlated)
Lệnh "xtgls" sẽ thực hiện hồi quy GLS, giúp bạn xử lý các vấn đề về phương sai thay đổi và tự tương quan, từ đó cung cấp các ước lượng hồi quy chính xác hơn.
Trên đây là quy trình 13 bước chạy luận văn dữ liệu bảng panel bằng Stata. Việc thực hiện đúng các bước này sẽ giúp ta phân tích dữ liệu một cách hiệu quả và đạt được kết quả nghiên cứu chính xác.
Như vậy các bạn có thể hiểu rõ hơn về quy trình, các bước cần chạy trong bài luận văn định lượng của mình. Các bạn có thắc mắc hoặc cần trao đổi hỗ trợ cứ liên hệ nhóm nhé
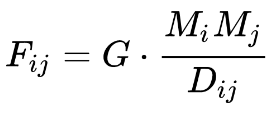
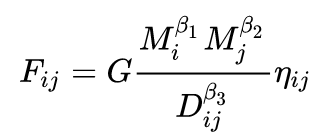
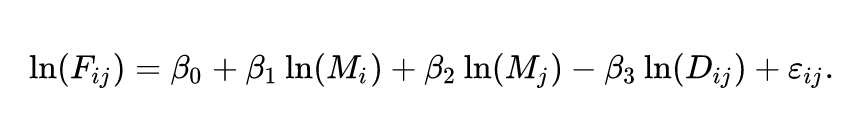
 đại diện cho khối lượng thương mại từ quốc gia i đến quốc gia j
đại diện cho khối lượng thương mại từ quốc gia i đến quốc gia j
 biểu thị khoảng cách giữa hai nước
biểu thị khoảng cách giữa hai nước