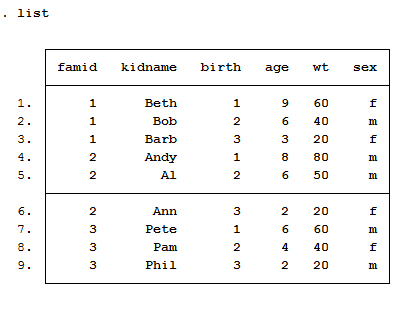
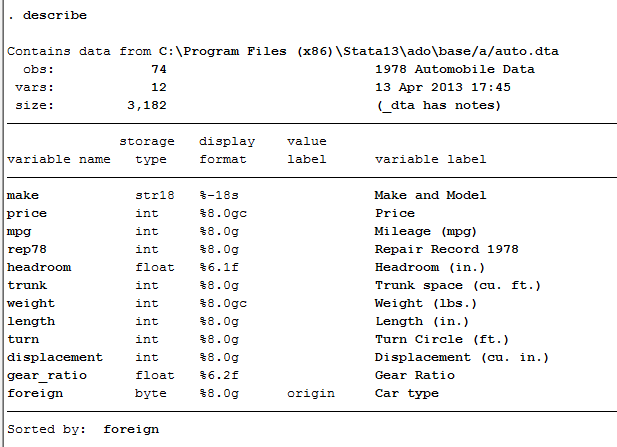
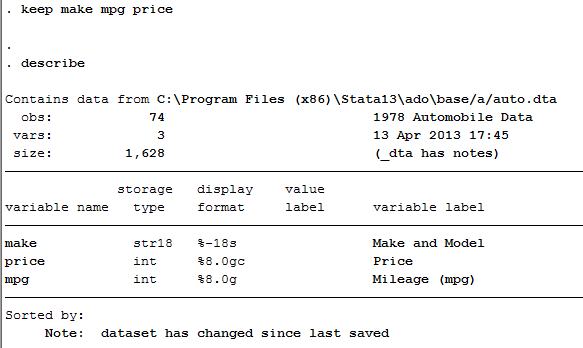
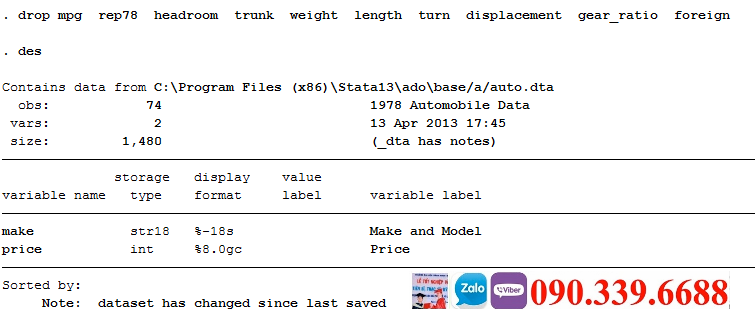
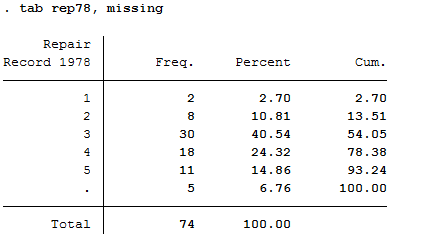
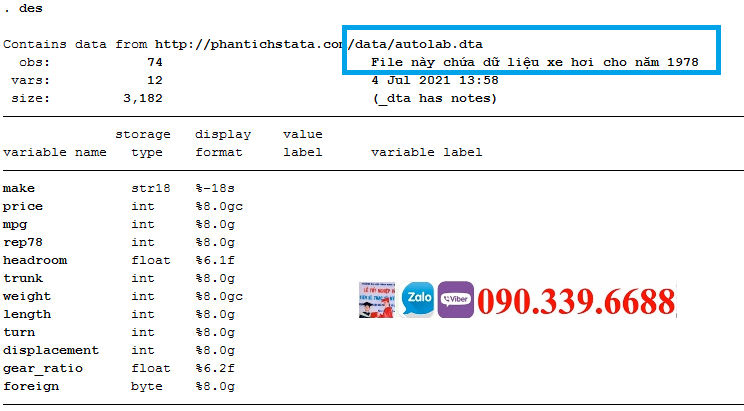
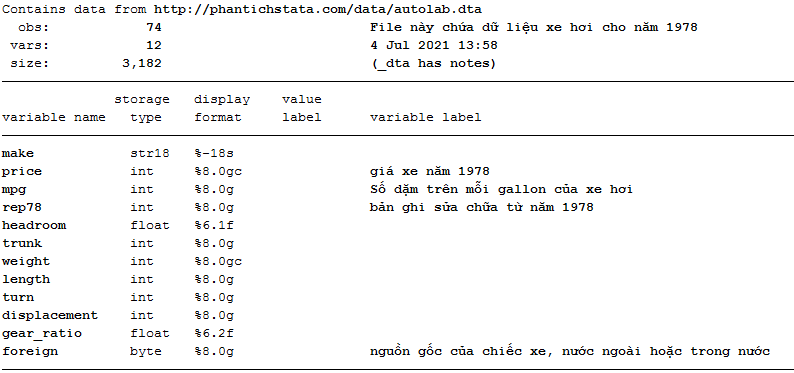
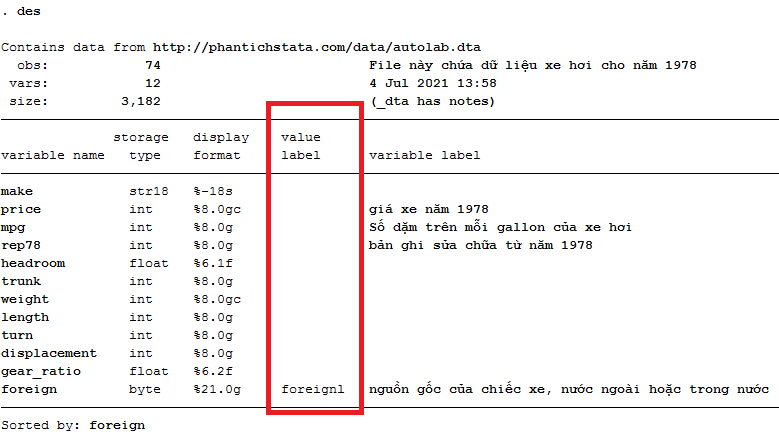
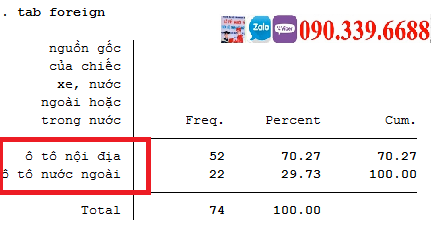
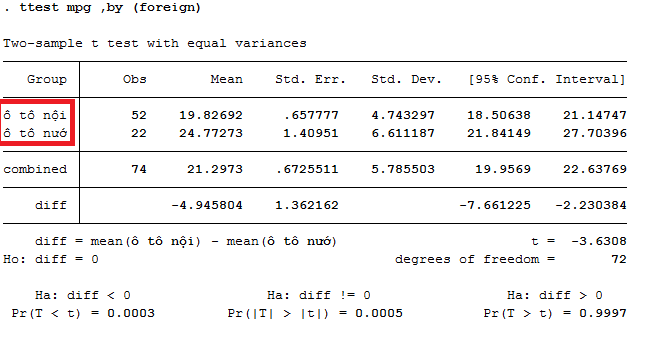
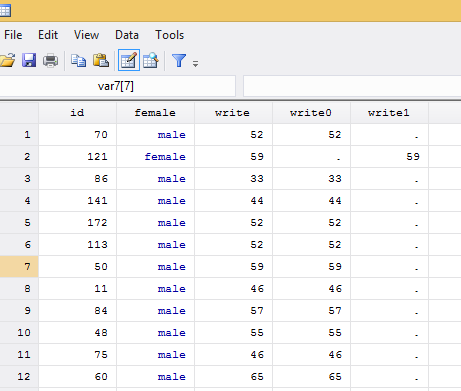
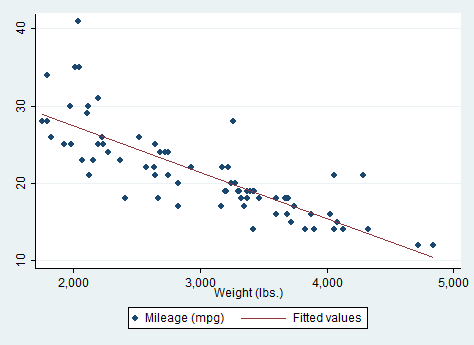
Phần này minh họa sức mạnh (và sự đơn giản) của Stata trong khả năng định hình lại các file dữ liệu. Những ví dụ này lấy các file số liệu rộng và định hình lại chúng thành dạng số liệu dài.
Trước mắt cần hiểu số liệu rộng wide là gì? Số liệu dài long là gì? Như ví dụ hình dưới, số liệu rộng là số liệu thu nhập income các năm khác nhau là các biến khác nhau, còn số liệu dài là số liệu thu nhập income các năm khác nhau là các dòng khác nhau.

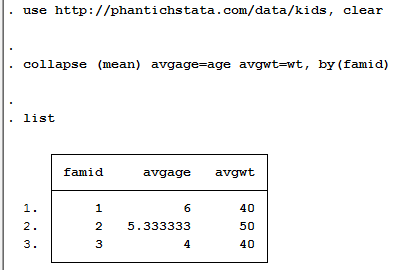
Định hình lại dữ liệu từ rộng thành dài
Ví dụ 1(i có một tham số)
Hãy nhập dữ liệu thu nhập của gia đình bên dưới theo câu lệnh
clear
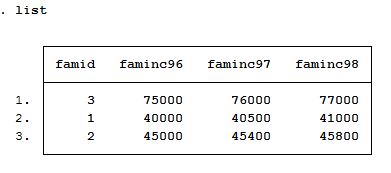
input famid faminc96 faminc97 faminc98
3 75000 76000 77000
1 40000 40500 41000
2 45000 45400 45800
end

Đây là thu nhập của hộ gia đình ở 3 năm 1996, 1997, 1998
Bây giờ sẽ chuyển dữ liệu lại, giá trị năm không nằm ở hàng ngang nữa mà nằm dạng cột dọc như ví dụ sau, vậy ta cần làm gì?

Các bạn gõ lệnh sau là bộ số liệu sẽ ra kết quả như mong muốn
reshape long faminc , i(famid) j(year)
Muốn quay lại như cũ bạn chỉ cần gõ lệnh
reshape wide
Ví dụ 2 (i có hai tham số)
Ta nhập số liệu như sau để có số liệu
clear
input famid birth ht1 ht2
1 1 2.8 3.4
1 2 2.9 3.8
1 3 2.2 2.9
2 1 2 3.2
2 2 1.8 2.8
2 3 1.9 2.4
3 1 2.2 3.3
3 2 2.3 3.4
3 3 2.1 2.9
end
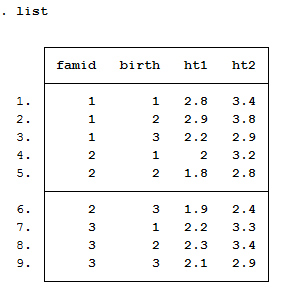
Ta có số liệu về chiều cao lúc 1 tuổi và chiều cao lúc 2 tuổi của các trẻ em, giờ ta sẽ chuyển về số liệu dọc long nhé
reshape long ht,i(famid birth) j(age)
Lưu ý là tham số của i phải là khóa chính, nghĩa là không được trùng, nên ở đây cần kết hợp hai giá trị famid và birth để tạo thành giá trị của i.
Kết quả như sau:

Ví dụ 3(i có hai tham số và mã hóa cho 2 biến luôn)
Ta nhập số liệu như sau để có số liệu
clear
input famid birth ht1 ht2 wt1 wt2
1 1 2.8 3.4 19 28
1 2 2.9 3.8 21 28
1 3 2.2 2.9 20 23
2 1 2 3.2 25 30
2 2 1.8 2.8 20 33
2 3 1.9 2.4 22 33
3 1 2.2 3.3 22 28
3 2 2.3 3.4 20 30
3 3 2.1 2.9 22 31
end
Ở đây số liệu tương tự ví dụ 2, và có thêm giá trị cân nặng lúc 1 tuổi và 2 tuổi. Bây giờ ta sẽ dùng lệnh sau để chuyển thành dữ liệu dọc long nhé.
reshape long ht wt, i ( famid birth) j ( age)
Kết quả như sau:

Ví dụ 4: hậu tố là chữ, không phải số
Các ví dụ ở trên thì các hậu tố đều là số, ví dụ 1 tuổi 2 tuổi, còn nếu là chữ thì ví dụ này sẽ xử lý như sau:

Ví dụ này là có tên cha tên mẹ, tiền lương của cha và tiền lương của mẹ.
clear
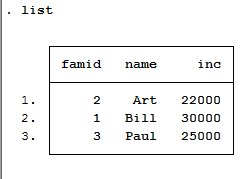
input famid str4 ten_cha tien_cha str4 ten_me tien_me
1 Bill 30000 Bess 15000
2 Art 22000 Amy 18000
3 Paul 25000 Pat 50000
end
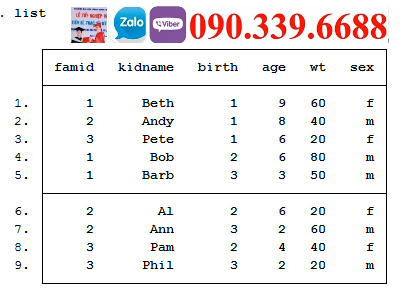
list
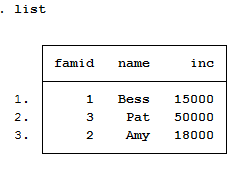
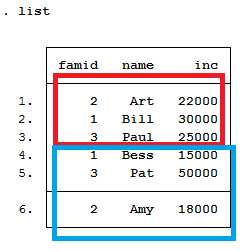
reshape long ten_ tien_, i( famid) j(chame) string
list

Tóm lại cú pháp lệnh reshape long như sau
reshape long stem-of-wide-vars, i(wide-id-var) j(var-for-suffix)
- stem-of-wide-vars: là gốc của các biến rộng, ví dụ: faminc
- wide-id-var là biến xác định tính duy nhất của số liệu, ví dụ famid
- var-for-suffix là biến sẽ chứa hậu tố của các biến số rộng, ví dụ: năm